Format
Scenario configuration example
A way to detect a http scanner might be to track the number of distinct non-existing pages it's requesting. The scenario might look like this:
type: leaky
name: crowdsecurity/http-scan-uniques_404
description: "Detect multiple unique 404 from a single ip"
filter: "evt.Meta.service == 'http' && evt.Meta.http_status in ['404', '403', '400']"
groupby: "evt.Meta.source_ip"
distinct: "evt.Meta.http_path"
capacity: 5
leakspeed: "10s"
blackhole: 5m
labels:
service: http
confidence: 3
spoofable: 0
classification:
- attack.T1595
behavior: "http:scan"
service: http
label: "Multiple unique 404 detection"
remediation: true
Scenario directives
type
type: leaky|trigger|counter|conditional|bayesian
Defines the type of the bucket. Currently five types are supported :
leaky: a leaky bucket that must be configured with a capacity and a leakspeedtrigger: a bucket that overflows as soon as an event is poured (it is like a leaky bucket is a capacity of 0)counter: a bucket that only overflows every duration. It is especially useful to count things.conditional: a bucket that overflows when the expression given inconditionreturns true. Useful if you want to look back at previous events that were poured to the bucket (to detect impossible travel or more behavioral patterns for example). It can't overflow like a leaky bucket and its capacity is ignored. Incase the conditional bucket is meant to be used to hold a large number of events, consider use the cashe_size field.bayesian: a bucket that runs bayesian inference internally. The overflow will trigger when the posterior probability reaches the threshold. This is useful for instance if the behaivor is a combination of events which alone wouldn't be worthy of suspicious.
Examples:
Leaky
The bucket will leak one item every 10 seconds, and can hold up to 5 items before overflowing.
type: leaky
...
leakspeed: "10s"
capacity: 5
...
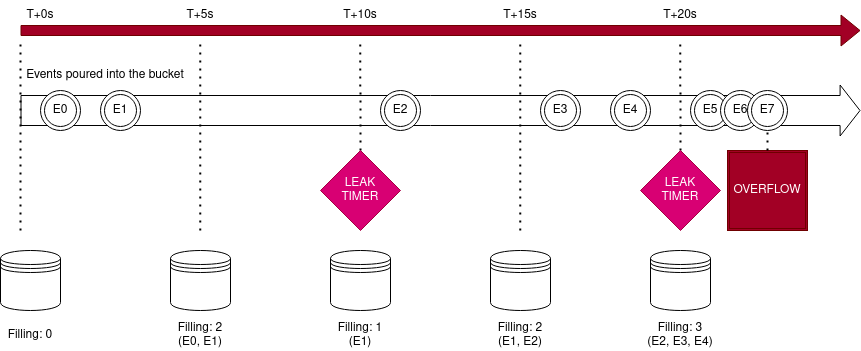
- The bucket is created at
t+0s - E0 is poured at
t+2s, bucket is at 1/5 capacity - E1 is poured at
t+4s, bucket is at 2/5 capacity - At
t+10sthe bucket leaks one item, is now at 1/5 capacity - E2 is poured at
t+11s, bucket is at 2/5 capacity - E3 and E4 are poured around
t+16s, bucket is at 4/5 capacity - At
t+20sthe bucket leaks one item, is now at 3/5 capacity - E5 and E6 are poured at
t+23s, bucket is at 5/5 capacity - when E7 is poured at
t+24s, the bucket is at 6/5 capacity and overflows
Trigger
The bucket will instantly overflow whenever an ip lands on a 404.
type: trigger
...
filter: "evt.Meta.service == 'http' && evt.Meta.http_status == '404'"
groupby: evt.Meta.source_ip
...
Counter
The bucket will overflow 20s after the first event is poured.
type: counter
...
filter: "evt.Meta.service == 'http' && evt.Meta.http_status == '404'"
duration: 20s
...
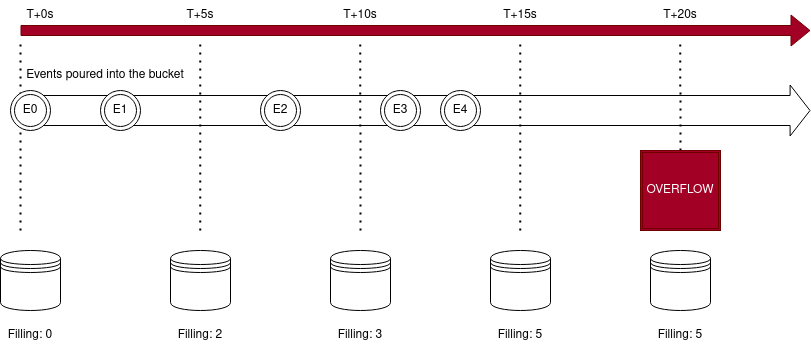
- The bucket is created at
t+0s - E0 is poured at
t+0s, count is at 1 - E1 is poured at
t+4s, count is at 2 - E2 is poured at
t+8s, count is at 3 - E3 is poured at
t+12s, count is at 4 - E4 is poured at
t+14s, count is at 5 - At
t+20sthe bucket overflows with a count of 5
Conditional
This bucket will overflow when the condition is true. In this example it will overflow if a user sucessfully authenticates after failing 5 times previously. For a more in depth look, check out our blogpost on the topic.
type: conditional
...
filter: "evt.Meta.service == 'ssh'"
...
condition: |
count(queue.Queue, #.Meta.log_type == 'ssh_failed-auth') > 5 and count(queue.Queue, #.Meta.log_type == 'ssh_success-auth') > 0
...
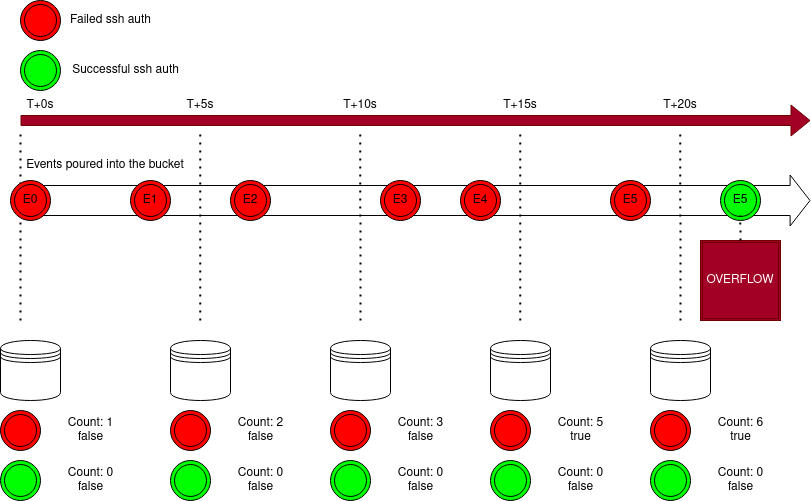
- The bucket is created at
t+0s - E0 is poured at
t+0s - E1 is poured at
t+4s - E2 is poured at
t+6s - E3 is poured at
t+12s - E4 is poured at
t+14s,count(queue.Queue, #.Meta.log_type == 'ssh_failed-auth') > 5now evaluates true - E5 is poured at
t+18s - when E6 is poured at
t+24s,count(queue.Queue, #.Meta.log_type == 'ssh_success-auth') > 0also evaluates true and the bucket overflows
Bayesian
The bayesian bucket is based on the concept of bayesian inference. The bucket overflows if the bayesian posterior is bigger than the threshold. To calculate the posterior, the bucket will run bayesian updates for all the conditions defined in the scenario.
The bucket starts with a predefined prior P(Evil). Whenever an event is poured the bucket will iteratively calculate P(Evil|State(Condition_i)) for all defined conditions. The resulting posterior value for P(Evil) is then compared against the threshold. If the threshold is exceeded the bucket overflows. If the threshold is not exceeded, the bucket is reset by setting P(Evil) back to the prior.
In case the condition is costly to evaluate, the guillotine can be set. This will stop the condition from being evaluated after the first time it evaluates to true. The bayesian update will assume that the condition is true for every iteration after that.
type: bayesian
...
filter: "evt.Meta.log_type == 'http_access-log' || evt.Meta.log_type == 'ssh_access-log'"
...
bayesian_prior: 0.5
bayesian_threshold: 0.8
bayesian_conditions:
- condition: any(queue.Queue, {.Meta.http_path == "/"})
prob_given_evil: 0.8
prob_given_benign: 0.2
- condition: evt.Meta.ssh_user == "admin"
prob_given_evil: 0.9
prob_given_benign: 0.5
guillotine : true
...
leakspeed: 30s
capacity: -1
...
Guidelines on setting the bayesian parameters can be found below
name
name: github_account_name/my_scenario_name
or
name: my_author_name/my_scenario_name
The name is mandatory.
It must be unique. This will define the scenario's name in the hub.
description
description: A scenario that detect XXXX behavior
The description is mandatory.
It is a short description, probably one sentence, describing what it detects.
references
references:
- A reference to third party documents.
The references is optional.
A reference to third party documents. This is a list of string.
filter
filter: expression
filter must be a valid expr expression that will be evaluated against the event.
If filter evaluation returns true or is absent, event will be pour in the bucket.
If filter returns false or a non-boolean, the event will be skipped for this bucket.
Here is the expr documentation.
Examples :
evt.Meta.log_type == 'telnet_new_session'evt.Meta.log_type in ['http_access-log', 'http_error-log'] && evt.Parsed.static_ressource == 'false'evt.Meta.log_type == 'ssh_failed-auth'
duration
duration: 45s
duration: 10m
Only applies to counter buckets.
A duration after which the bucket will overflow. The format must be compatible with golang ParseDuration format
Examples :
type: counter
name: crowdsecurity/ban-reports-ssh_bf_report
description: "Count unique ips performing ssh bruteforce"
filter: "evt.Overflow.Scenario == 'ssh_bruteforce'"
distinct: "evt.Overflow.Source_ip"
capacity: -1
duration: 10m
labels:
service: ssh
confidence: 3
spoofable: 0
classification:
- attack.T1110
label: "SSH Bruteforce"
behavior : "ssh:bruteforce"
remediation: true
cti: true
groupby
groupby: evt.Meta.source_ip
An expression that must return a string. This string will be used as a partition for the buckets.
Examples
Here, each source_ip will get its own bucket.
type: leaky
...
groupby: evt.Meta.source_ip
...
Here, each unique combo of source_ip + target_username will get its own bucket.
type: leaky
...
groupby: evt.Meta.source_ip + '--' + evt.Parsed.target_username
...
distinct
distinct: evt.Meta.http_path
An expression that must return a string. The event will be poured only if the string is not already present in the bucket.
Examples
This will ensure that events that keep triggering the same .Meta.http_path will be poured only once.
type: leaky
...
distinct: "evt.Meta.http_path"
...
Assuming we received the 3 following events :
evt.Meta.http_path = /evt.Meta.http_path = /testevt.Meta.http_path = /
Only the first 2 events will be poured to the bucket.
The 3rd one will not be poured as the bucket already contains an event with evt.Meta.http_path == /
capacity
capacity: 5
Only applies to leaky buckets.
A positive integer representing the bucket capacity.
If there are more than capacity item in the bucket, it will overflow.
Should be set to -1 in most situations for conditional buckets.
leakspeed
leakspeed: "10s"
Only applies to leaky and conditional buckets.
A duration that represent how often an event will be leaking from the bucket.
Must be compatible with golang ParseDuration format.
condition
condition: |
len(queue.Queue) >= 2
and Distance(queue.Queue[-1].Enriched.Latitude, queue.Queue[-1].Enriched.Longitude,
queue.Queue[-2].Enriched.Latitude, queue.Queue[-2].Enriched.Longitude) > 100
Only applies to conditional buckets.
Make the bucket overflow when it returns true. The expression is evaluated each time an event is poured to the bucket.
bayesian_prior
bayesian_prior: 0.03
Only applies to bayesian buckets.
This is the initial probability that a given IP falls under the behavior you want to catch. A good first estimate for this parameter is #evil_ips/#total_ips, where evil are all the IPs you want to catch with this scenario.
bayesian_threshold
bayesian_threshold: 0.5
Only applies to bayesian buckets.
This defines the threshold you want the posterior to exceed to trigger the bucket. This parameter can be finetuned according to individual preference. A higher threshold will decrease the number of false positives at the cost of missing some true positives while decreasing the threshold will catch more true positives at the cost of more false positives. If the term precision vs recall tradeoff is familiar to the reader, this is an application of this principle.
bayesian_conditions
bayesian_conditions:
- condition: any(queue.Queue, {.Meta.http_path == "/"})
prob_given_evil: 0.8
prob_given_benign: 0.2
- condition: evt.Meta.ssh_user == "admin"
prob_given_evil: 0.9
prob_given_benign: 0.5
guillotine : true
Only applies to bayesian buckets.
Bayesian conditions are the heart of the bayesian bucket. Every condition represents an event we want to do a bayesian update for. Every time the inference is ran we evaluate the condition. The two parameters prob_given_evil and prob_given_benign are called likelihoods and are used during the update. They represent the two conditional probabilities P(condition == true | IP is evil) and P(condition == true | IP is benign) respectively.
A good estimate for the likelihoods is to look at all events in your logs and use the ratios #evil_ips_satisfying_condition/#evil_ips resp. #benign_ips_satisfying_condition/#benign_ips. If the results of the scenario are imprecise one should either add more conditions or play around with the threshold. It is not recommended to individually adjust the likelihoods as this leads to overfitting.
If the evalutaion of the condition is particularly expensive, one can add a guillotine. This will prevent the condition from being evaluated after the first time it evaluates to true. The bayesian updates will from then on out only consider the case condition == true.
Note: prob_given_evil and prob_given_benign do not have to sum up to 1 as they describe different events.
labels
labels:
service: ssh
confidence: 3
spoofable: 0
classification:
- attack.T1110
label: "SSH Bruteforce"
behavior : "ssh:bruteforce"
remediation: true
Labels is a list of label: values that provide context to an alert.
The value can be of any type (string, list, object ...).
Some labels are required, but other labels can be added.
note: the labels are (currently) not stored in the database, nor they are sent to the API.
remediation
type: bool
The remediation label, if set to true indicate if the originating IP should be banned.
classification
type: list
This is a list of classifications that we can attribute to a scenario in the form:
<classification_type>.<classification_id>
Only cve and attack (for Mitre ATT&CK) are supported.
- For a mitre_attack, this is the format:
attack.<technique_id> # example: attack.T1595
Where technique_id is a Mitre ATT&CK technique. You can find the list here.
- For a CVE this is the format:
cve.<cve_id> # example: cve.CVE-2021-44228
behavior
type: string
behavior is a string in the form:
<service_or_os>:<attack_type>
note: when the service is available, prefer to use the service instead of the OS.
The behavior should exist in this file: https://github.com/crowdsecurity/hub/blob/master/taxonomy/behaviors.json
label
type: string (optional)
label is a human-readable name for the scenario.
For example, for the crowdsecurity/apache_log4j2_cve-2021-44228 scenario it is Log4j CVE-2021-44228 .
spoofable
type: int [0-3]
The chance between 0 and 3 that the attacker behind the attack can spoof its origin. 0 means not spoofable and 3 means spoofable.
confidence
type: int [0-3]
The confidence note between 0 and 3 that the scenario will not trigger false positive. 0 means no confidence and 3 means high confident.
cti
type: bool [true|false]
Specify that the scenario is used mostly for auditing and not to detect threat.
false means that the scenario is not to detect threat.
blackhole
blackhole: 10m
A duration for which a bucket will be "silenced" after overflowing. This is intended to limit / avoid spam of buckets that might be very rapidly triggered.
The blackhole only applies to the individual bucket rather than the whole scenario.
Must be compatible with golang ParseDuration format.
Example
The same source_ip won't be able to trigger this overflow more than once every 10 minutes.
The potential overflows in the meanwhile will be discarded (but will still appear in logs as being blackholed).
type: trigger
...
blackhole: 10m
groupby: evt.Meta.source_ip
debug
debug: true|false
default: false
If set to to true, enabled scenario level debugging.
It is meant to help understanding scenario behavior by providing contextual logging :
debug of filters and expression results
DEBU[31-07-2020 16:34:58] eval(evt.Meta.log_type in ["http_access-log", "http_error-log"] && any(File("bad_user_agents.txt"), {evt.Parsed.http_user_agent contains #})) = TRUE cfg=still-feather file=config/scenarios/http-bad-user-agent.yaml name=crowdsecurity/http-bad-user-agent
DEBU[31-07-2020 16:34:58] eval variables: cfg=still-feather file=config/scenarios/http-bad-user-agent.yaml name=crowdsecurity/http-bad-user-agent
DEBU[31-07-2020 16:34:58] evt.Meta.log_type = 'http_access-log' cfg=still-feather file=config/scenarios/http-bad-user-agent.yaml name=crowdsecurity/http-bad-user-agent
DEBU[31-07-2020 16:34:58] evt.Parsed.http_user_agent = 'Mozilla/5.00 (Nikto/2.1.5) (Evasions:None) (Test:002810)' cfg=still-feather file=config/scenarios/http-bad-user-agent.yaml name=crowdsecurity/http-bad-user-agent
reprocess
reprocess: true|false
default: false
If set to true, the resulting overflow will be sent again in the scenario/parsing pipeline.
It is useful when you want to have further scenarios that will rely on past-overflows to take decisions.
cache_size
cache_size: 5
By default, a bucket holds capacity events "in memory". However, for a number of cases, you don't want this, as it might lead to excessive memory consumption.
By setting cache_size to a positive integer, we can control the maximum in-memory cache size of the bucket, without changing its capacity and such. It is useful when buckets are likely to stay alive for a long time or ingest a lot of events to avoid storing a lot of events in memory.
Cache size will affect the number of events you receive within an alert. If you set a cache size to 5, you will only receive the last 6 events (Cache size including the overflow) in the alert. Any pipelines that rely on the alert object will be affected (Notification, Profiles, Postoverflow).
overflow_filter
overflow_filter: any(queue.Queue, { .Enriched.IsInEU == "true" })
overflow_filter is an expression that is run when the bucket overflows.
If this expression is present and returns false, the overflow will be discarded.
cancel_on
cancel_on: evt.Parsed.something == 'somevalue'
cancel_on is an expression that runs on each event poured to the bucket.
If the cancel_on expression returns true, the bucket is immediately destroyed (and doesn't overflow).
data
data:
- source_url: https://URL/TO/FILE
dest_file: LOCAL_FILENAME
[type: (regexp|string)]
dest_file is relative to the data directory set within config.yaml default per OS:
- Linux:
/var/lib/crowdsec/data - Freebsd:
/var/db/crowdsec/data - Windows:
C:\programdata\crowdsec\data
data allows to specify an external source of data.
The source_url section is only relevant when cscli is used to install scenario from hub, as it will download the source_url and store it in the dest_file within the data directory.
When the scenario is not installed from the hub, CrowdSec will not download the source_url, however, if the file exists at dest_file within the data directory it will still be loaded into memory.
The type is mandatory if you want to evaluate the data in the file, and should be regex for valid (re2) regular expression per line or string for string per line.
The regexps will be compiled, the strings will be loaded into a list and both will be kept in memory.
Without specifying a type, the file will be downloaded and stored as file and not in memory.
You can refer to the content of the downloaded file(s) by using either the File() or RegexpInFile() function in an expression:
filter: 'evt.Meta.log_type in ["http_access-log", "http_error-log"] and any(File("backdoors.txt"), { evt.Parsed.request contains #})'
Example
name: crowdsecurity/cdn-whitelist
...
data:
- source_url: https://www.cloudflare.com/ips-v4
dest_file: cloudflare_ips.txt
type: string
Caching feature
Since 1.5, it is possible to configure additional cache for RegexpInFile() :
- input data (hashed with xxhash)
- associated result (true or false)
Cache behavior can be configured:
- strategy: LRU, LFU or ARC
- size: maximum size of cache
- ttl: expiration of elements
- cache: boolean (true by default if one of the fields is set)
This is typically useful for scenarios that needs to check on a lot of regexps.
Example configuration:
type: leaky
#...
data:
- source_url: https://raw.githubusercontent.com/crowdsecurity/sec-lists/master/web/bad_user_agents.regex.txt
dest_file: bad_user_agents.regex.txt
type: regexp
strategy: LRU
size: 40
ttl: 5s
format
format: 2.0
CrowdSec has a notion of format support for parsers and scenarios for compatibility management.
Running cscli version will show you such compatibility matrix :
sudo cscli version
2020/11/05 09:35:05 version: v0.3.6-183e34c966c475e0d2cdb3c60d0b7426499aa573
2020/11/05 09:35:05 Codename: beta
2020/11/05 09:35:05 BuildDate: 2020-11-04_17:56:46
2020/11/05 09:35:05 GoVersion: 1.13
2020/11/05 09:35:05 Constraint_parser: >= 1.0, < 2.0
2020/11/05 09:35:05 Constraint_scenario: >= 1.0, < 3.0
2020/11/05 09:35:05 Constraint_api: v1
2020/11/05 09:35:05 Constraint_acquis: >= 1.0, < 2.0
scope
scope:
type: Range
expression: evt.Parsed.mySourceRange
While most scenarios might focus on IP addresses, CrowdSec and Bouncers can work with any scope.
The scope directive allows you to override the default scope :
typeis a string representing the scope nameexpressionis anexprexpression that will be evaluated to fetch the value
let's imagine a scenario such as :
# ssh bruteforce
type: leaky
name: crowdsecurity/ssh-enforce-mfa
description: "Enforce mfa on users that have been bruteforced"
filter: "evt.Meta.log_type == 'ssh_failed-auth'"
leakspeed: "10s"
capacity: 5
groupby: evt.Meta.source_ip
blackhole: 1m
labels:
service: ssh
type: bruteforce
remediation: true
scope:
type: username
expression: evt.Meta.target_user
and a profile such as :
name: enforce_mfa
filters:
- 'Alert.Remediation == true && Alert.GetScope() == "username"'
decisions:
- type: enforce_mfa
scope: "username"
duration: 1h
on_success: continue
the resulting overflow will be :
$ ./cscli -c dev.yaml decisions list
+----+----------+---------------+-------------------------------+-------------+---------+----+--------+------------------+
| ID | SOURCE | SCOPE:VALUE | REASON | ACTION | COUNTRY | AS | EVENTS | EXPIRATION |
+----+----------+---------------+-------------------------------+-------------+---------+----+--------+------------------+
| 2 | crowdsec | username:rura | crowdsecurity/ssh-enforce-mfa | enforce_mfa | | | 6 | 59m46.121840343s |

